От восприятия к визуальному мышлению:
как добавить ИИ внутреннее «воображение»

За последние годы мультимодальные LLM (MLLM) научились распознавать объекты, читать подписи, отвечать на вопросы по изображению и даже неплохо объяснять, что происходит в кадре. Но у них есть упрямая слабость: как только задача требует не просто описать увиденное, а удержать визуальные детали в памяти и мысленно выполнить над ними несколько шагов преобразований, качество резко падает. Например, понять правило в матрице фигур, мысленно повернуть объект, предсказать результат простого «физического» действия или пройтись вниманием по схеме в правильном порядке.
Авторы работы Toward Cognitive Supersensing in Multimodal Large Language Model называют это разрывом между восприятием и визуальным мышлением. В современных подходах его часто пытаются закрыть текстовыми цепочками рассуждений: модель генерирует подробное объяснение шаг за шагом и якобы «думает». Проблема в том, что текст — неудобный интерфейс для пространственных операций. Когда вы в уме вращаете куб или достраиваете закономерность в узоре, вы не переводите каждую микропроверку в слова. Модели же вынуждены «сжимать» пространство в последовательность токенов, и на длинных визуальных задачах это превращается в узкое горлышко.
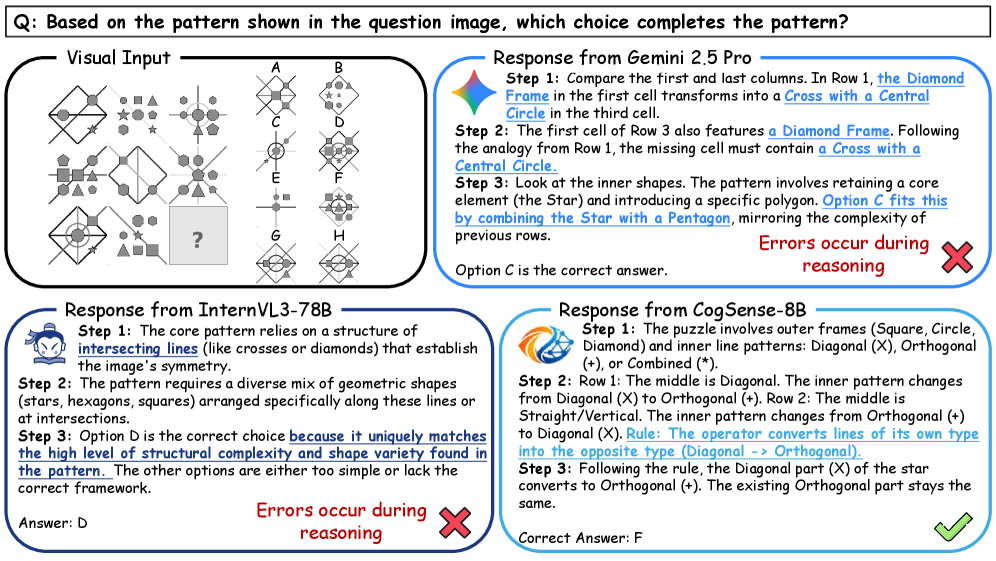
Бенчмарк, который проверяет не описание, а визуальное мышление
Чтобы измерять именно «визуальное мышление», авторы собрали CogSense-Bench и связанный с ним датасет CogSense-Dataset-105K. Вопросы распределены по пяти когнитивным измерениям: текучий интеллект (решение новых абстрактных задач), кристаллизованный интеллект (опора на выученные знания), зрительно‑пространственное мышление, мысленная симуляция и визуальные процедуры — то есть задачи, где важно уметь правильно направлять внимание и выполнять последовательность визуальных операций.
Смысл этого шага простой: если бенчмарк проверяет только распознавание, то модель может выглядеть умной, оставаясь «пассивной камерой с хорошим словарём». CogSense-Bench специально устроен так, чтобы без внутренней визуальной работы модель чаще ошибалась.

Идея когнитивной сверхчувствительности: «внутреннее зрительное воображение» в латентном пространстве
Ключевая идея статьи — перенести часть рассуждения из текста в пространство представлений, где живут визуальные признаки. Авторы предлагают парадигму Cognitive Supersensing: модель получает дополнительную голову LVIP (Latent Visual Imagery Prediction), которая учится предсказывать латентное визуальное представление правильного ответа. Проще говоря, помимо генерации текста модель параллельно строит внутренний «образ того, к чему она должна прийти», и это становится каркасом для многошагового решения.
Важно, что это не попытка заставить модель рисовать картинки пиксель в пиксель. Она работает с компактными эмбеддингами: такими внутренними векторами, которые кодируют визуальную структуру. В этом смысле подход близок к идее visuospatial sketchpad из когнитивной психологии: отдельная «черновая доска» для пространственных операций, которую не нужно каждый раз переводить в слова.

Как обучают: сначала хорошие рассуждения, потом привязка к «образу», затем RL
Обучение построено в несколько шагов. Сначала авторы получают цепочки рассуждений от модели-учителя и фильтруют их, чтобы не тащить в обучение галлюцинации и неверные ответы. Затем делают supervised fine-tuning: модель учится и генерировать ответ, и одновременно предсказывать латентный «визуальный образ» правильной опции через LVIP. А на финальном этапе добавляют обучение с подкреплением, где поощряются такие траектории рассуждений, которые согласованы с ответом не только в тексте, но и в латентном визуальном представлении. Это похоже на попытку дисциплинировать модель: «думай так, чтобы твои промежуточные внутренние состояния действительно вели к правильной визуальной цели».
Что получилось на практике
На CogSense-Bench модель CogSense-8B показывает среднюю точность 73.8%. Для сравнения, приведённый в статье GPT-5.2 набирает 40.3%, а многие другие сильные MLLM — в районе 30–37%. Особенно показательно, что LVIP даёт заметный вклад сверх обычного SFT, а добавление RL дальше улучшает результат.
При этом на «общих» бенчмарках вроде ScienceQA, GQA и других изменения в среднем не выглядят как грубое переобучение: модель остаётся сопоставимой с базовым бэкбоном в стандартных задачах, но резко прибавляет там, где нужно именно визуальное рассуждение. Дополнительно авторы проверяют обобщение вне домена на EMMA (картинные вопросы по химии и математике) и тоже видят прирост: например, математика растёт с 26.0 до 34.8.

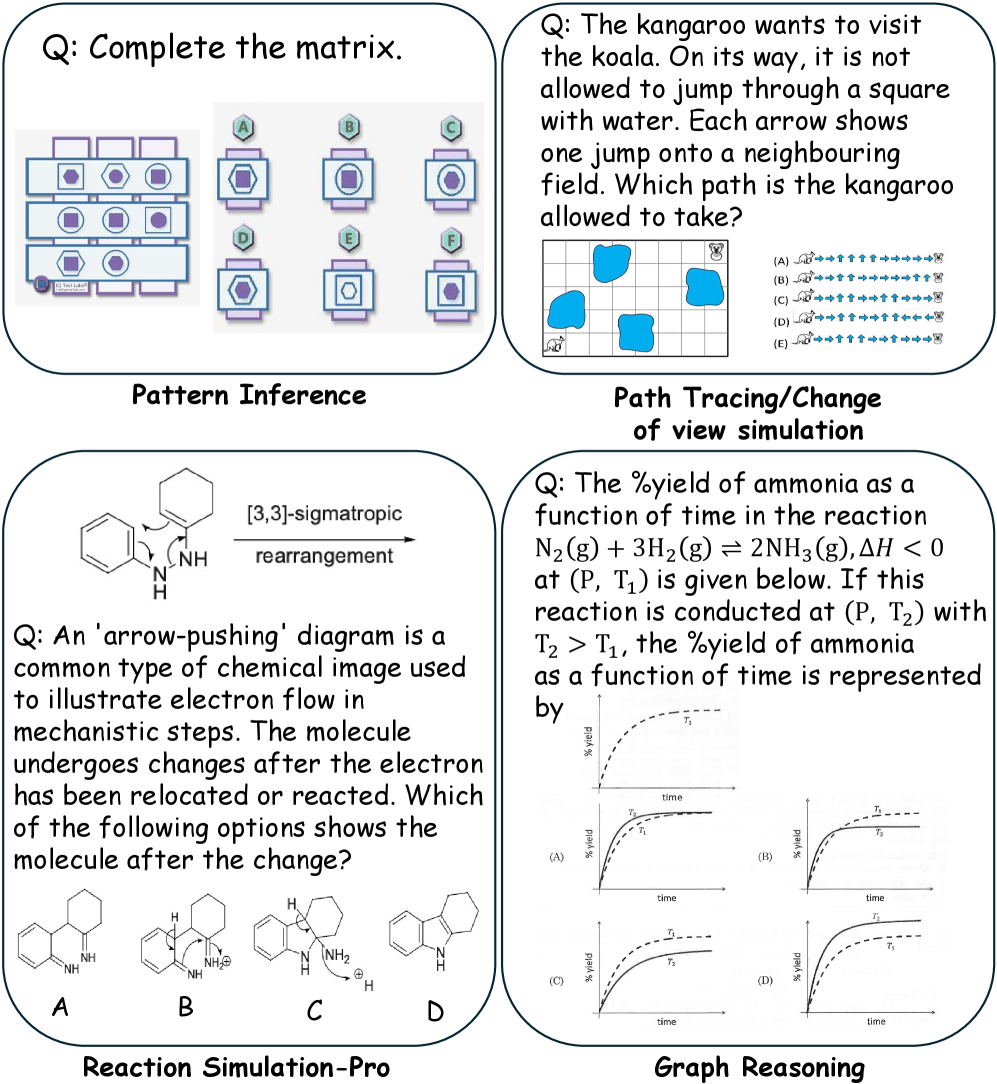
Почему это важно и куда может вести дальше
Эта работа формулирует то, что многие чувствовали на практике: больше цепочек рассуждений не гарантирует лучшего визуального мышления, потому что текст сам по себе плохо хранит и преобразует пространственные структуры. Cognitive Supersensing предлагает компромисс: язык остаётся для управления и объяснения, а внутренний визуальный «скелет» рассуждения живёт в латентном пространстве, ближе к тому, как работает модель мира в задачах предсказания состояний.
Если направление закрепится, мы можем увидеть MLLM, которые не только отвечают по картинке, но и действительно умеют делать внутреннюю симуляцию — не обязательно рисуя, но удерживая устойчивые визуальные состояния на протяжении многих шагов.