От статичных пайплайнов к адаптивным агентам:
как научить LLM выбирать действия, инструменты и бюджет под запрос

В мультиагентных системах один компонент системы планирует, другой проверяет, третий вызывает инструменты вроде поиска или калькулятора. И тут выясняется, что качество зависит не только от самой LLM, но и от того, как именно мы собрали эту «обвязку»: какой пайплайн выбрать, какие инструменты разрешить, сколько токенов выделить на рассуждение, какие промты дать каждому агенту.
Проблема в том, что на практике конфигурация обычно статична. Команда один раз подбирает удачный шаблон — и дальше гоняет его на всех запросах подряд. Из-за этого система часто ведёт себя неустойчиво и расточительно. Простому вопросу достаётся тяжёлая схема с поиском, голосованием и проверками, хотя можно было ответить напрямую. А сложный запрос, наоборот, может получить слишком короткий бюджет или не те инструменты. Плюс появляется классическая беда длинных контекстов: часть важной информации теряется в середине, и качество падает.
Авторы работы Learning to Configure Agentic AI Systems предлагают относиться к настройке не как к разовой инженерной задаче, а как к решению, которое нужно принимать заново для каждого запроса. Правда, тут же встаёт комбинаторный кошмар: даже в относительно небольшой системе легко набираются десятки тысяч вариантов (workflow × наборы инструментов × уровни бюджетов × варианты промтов). Перебирать это вручную или простым поиском слишком дорого.
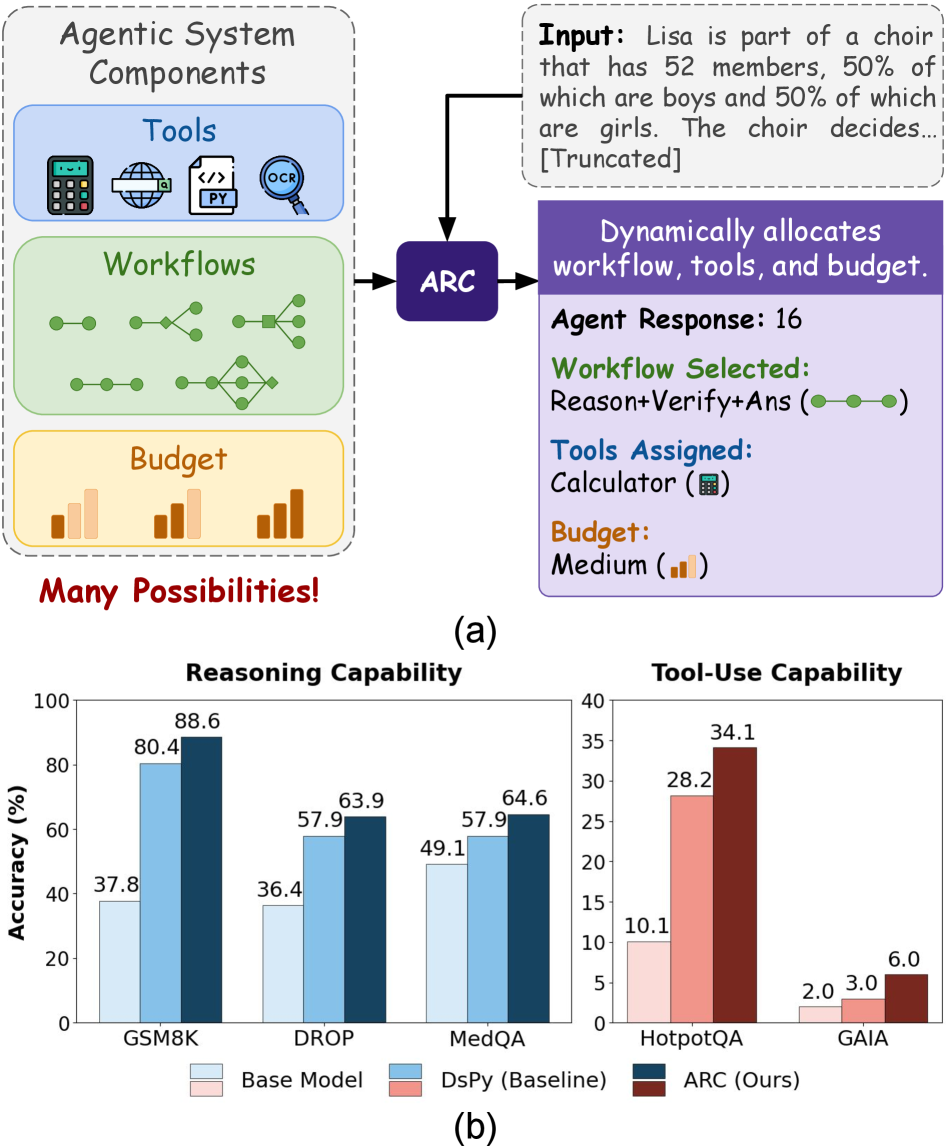
ARC: контроллер, который выбирает режим работы под запрос
Решение авторов называется ARC (Agentic Resource & Configuration learner). По сути это лёгкий обучаемый контроллер, который стоит поверх агентной системы и решает, как её запускать именно сейчас. Важно, что backbone LLM не дообучают — вместо этого обучают небольшие политики, которые выбирают конфигурацию.
ARC устроен иерархически. Такой разрез делает задачу более управляемой: вместо одной гигантской кнопки «выбери всё» система принимает решение по частям.
Верхний уровень
Политика решает «структуру»: какой workflow включить, какие инструменты разрешить, какой токен-бюджет выдать агентам.
Нижний уровень
Другая политика собирает промты из библиотеки смысловых фрагментов (например, добавить инструкцию разложить задачу на шаги или проверить вычисления).
Чтобы политика понимала, что перед ней за запрос, она получает его представление: эмбеддинг текста плюс простые признаки вроде длины, «числовой плотности» и индикаторов того, похоже ли задание на многошаговое рассуждение или на необходимость инструментов.
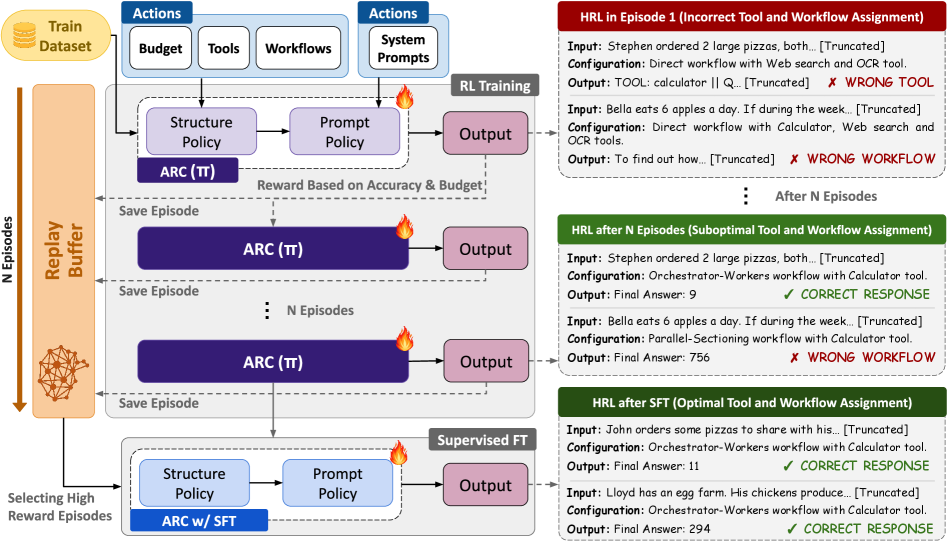
Как ARC учится: награда за правильность и штраф за стоимость
Авторы формулируют обучение с подкреплением (RL): на каждом запросе система выбирает конфигурацию, запускает агентный пайплайн и получает награду. Награда учитывает два главных фактора: ответ правильный или нет, и сколько стоила попытка по шагам/токенам/времени. Так ARC вынуждают не просто «выжимать максимум точности», а искать баланс: где-то стоит запустить проверяющий цикл, а где-то лучше ответить быстро.
Есть тонкий момент с инструментами: можно разрешить веб-поиск, но LLM в итоге его не вызовет. Поэтому авторы добавляют shaping-награду, которая поощряет выделять инструменты тогда, когда они реально будут использованы, и штрафует за лишние разрешения без дела.
Ещё одна важная инженерная деталь — маскирование действий: часть комбинаций просто не имеет смысла (например, назначать инструменты агентам, которых выбранный пайплайн не использует). Маскирование выкидывает такие варианты и облегчает обучение.

После этапа RL авторы делают второй шаг: берут лучшие траектории (top 30% по награде среди правильных) и проводят supervised fine-tuning (SFT) политик. Это снижает случайность и делает поведение более стабильным: политика фиксирует найденные удачные режимы, вместо того чтобы каждый раз слегка колебаться.
Что получилось на бенчмарках и почему это важно
ARC проверяют на задачах рассуждения (GSM8k, DROP, MedQA) и на tool-augmented QA (HotpotQA, GAIA). На примере Qwen 2.5 7B Instruct система даёт резкий скачок относительно базовой модели с инструментами:
На HotpotQA и GAIA прирост тоже заметен, хотя абсолютные значения там ниже — задачи упираются в знания и поиск. Отдельно интересно, что ARC не «залипает» в одном любимом пайплайне. В анализе видно разнообразие используемых схем: для разных датасетов и типов вопросов политика выбирает разные паттерны, а не повторяет один и тот же тяжёлый конвейер.
Наконец, авторы показывают практичную метрику: компромисс точность–стоимость. ARC-решения оказываются на границе Парето или формируют её, то есть дают лучшую точность при той же цене или ту же точность дешевле, чем фиксированные и поисковые подходы.
В разборе ошибок приятная деталь: доля ошибок именно конфигурации политики меньше 10% на всех датасетах. В reasoning-задачах основная боль — собственно ошибки рассуждения, а в задачах с инструментами — пробелы в знаниях или неудачный retrieval.
Что это меняет в подходе к агентным системам
Главный вывод работы: подход one size fits all для агентных LLM-систем слишком дорогой и часто неоптимальный. Гораздо выгоднее научиться подбирать пайплайны, инструменты, бюджеты и промты под конкретный запрос, и делать это не руками, а обучаемой политикой.
ARC показывает, что такой контроллер может быть лёгким, обучаться без обновления основной LLM и при этом давать ощутимую прибавку качества вместе с экономией токенов и времени. Отдельно стоит отметить аккуратность конструкции: иерархия решений, маскирование недопустимых действий и финальная стабилизация через SFT выглядят, как разумный ответ на реальную проблему огромного комбинаторного пространства.